Tutel: An efficient mixture-of-experts implementation for large DNN model training
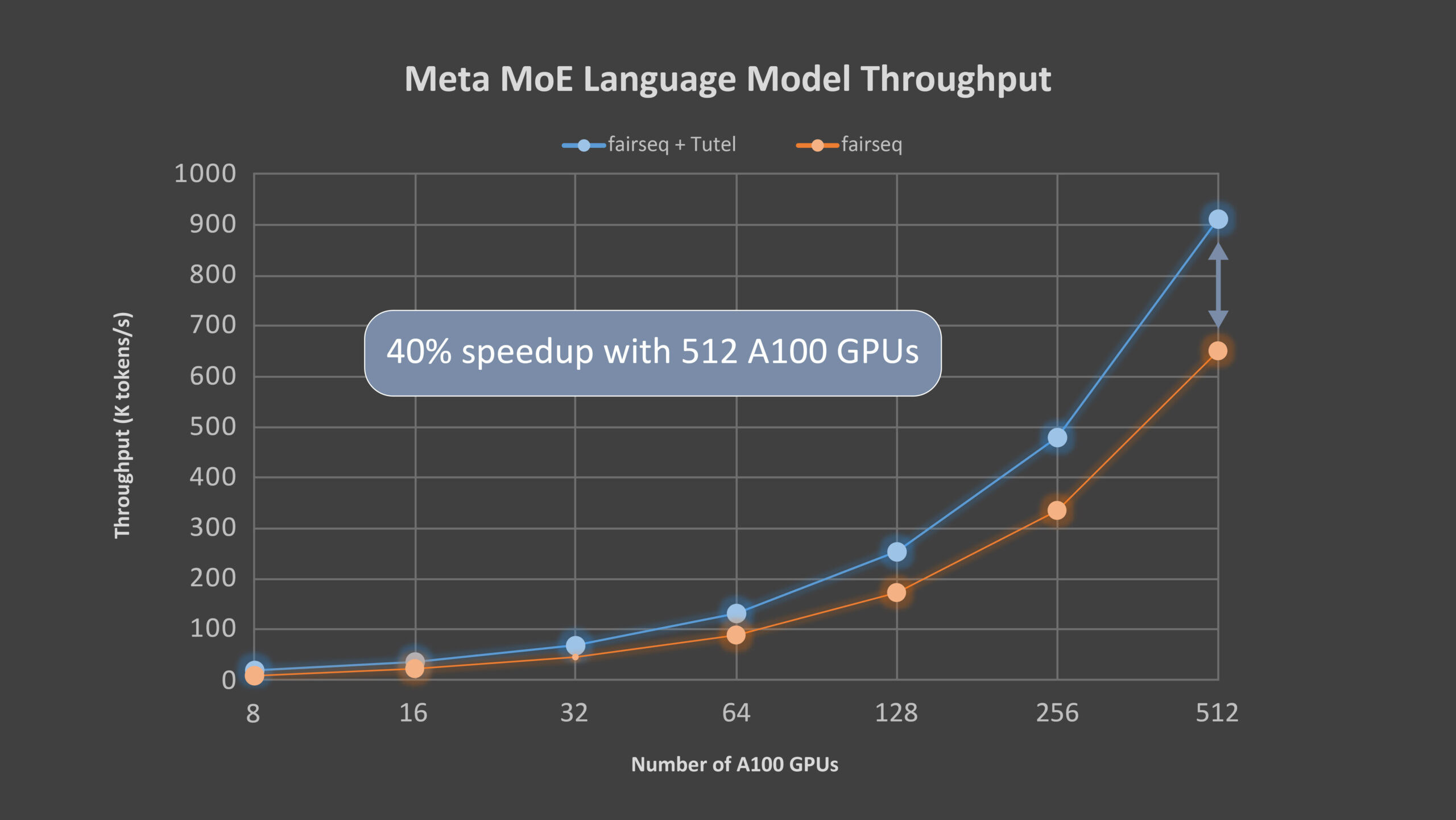
Mixture of experts (MoE) is a deep learning model architecture in which computational cost is sublinear to the number of parameters, making scaling easier. Nowadays, MoE is the only approach demonstrated to scale deep learning models to trillion-plus parameters, paving the way for models capable of learning even more information and powering computer vision, speech recognition,