Towards Fast, Controllable and Lightweight Text-to-Speech synthesis
FCL-Taco2
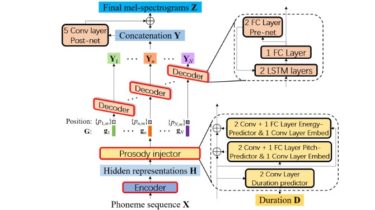
Block diagram of FCL-taco2, where the decoder generates mel-spectrograms in AR mode within each phoneme and is shared for all phonemes.
Training and inference scripts for FCL-taco2
Environment
- python 3.6.10
- torch 1.3.1
- chainer 6.0.0
- espnet 8.0.0
- apex 0.1
- numpy 1.19.1
- kaldiio 2.15.1
- librosa 0.8.0
Training and inference:
- Step1. Data preparation & preprocessing
-
Download LJSpeech
-
Unpack downloaded LJSpeech-1.1.tar.bz2 to /xx/LJSpeech-1.1
-
Obtain the forced alignment information by using Montreal forced aligner tool. Or you can download our alignment results, then unpack it to /xx/TextGrid
-
Preprocess the dataset to extract mel-spectrograms, phoneme duration, pitch, energy and phoneme sequence by:
python preprocessing.py --data-root /xx/LJSpeech-1.1 --textgrid-root /xx/TextGrid