Introduction to StanfordNLP: An Incredible State-of-the-Art NLP Library for 53 Languages (with Python code)
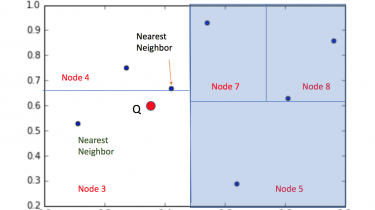
Introduction A common challenge I came across while learning Natural Language Processing (NLP) – can we build models for non-English languages? The answer has been no for quite a long time. Each language has its own grammatical patterns and linguistic nuances. And there just aren’t many datasets available in other languages. That’s where Stanford’s latest NLP library steps in – StanfordNLP. I could barely contain my excitement when I read the news last week. The authors claimed StanfordNLP could support more […]
Read more