How to Reduce Variance in a Final Machine Learning Model
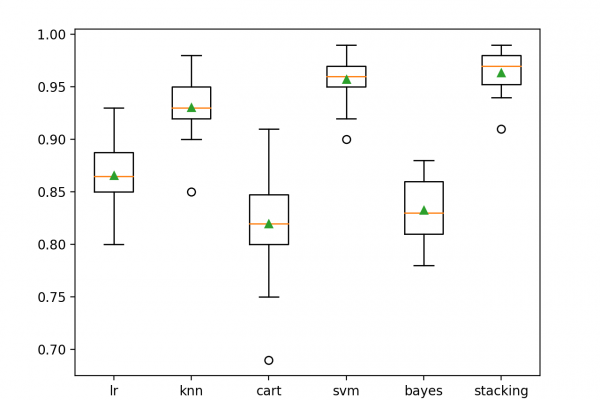
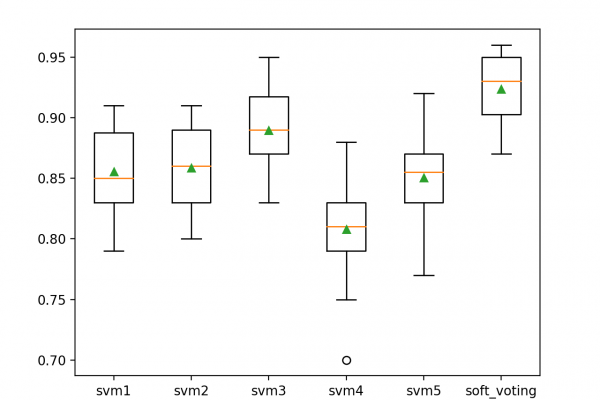
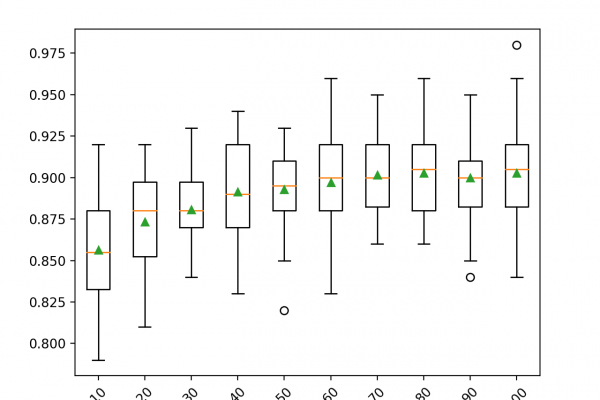
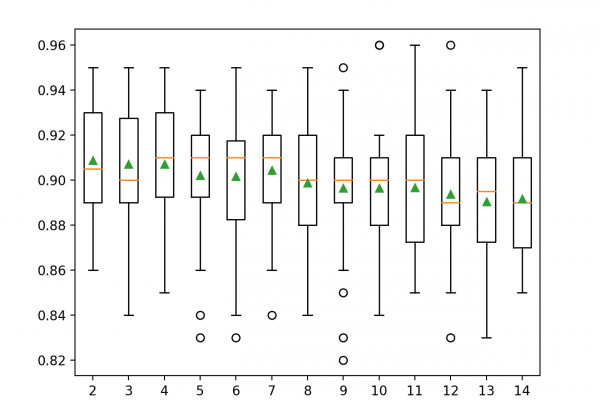
Last Updated on June 26, 2020 A final machine learning model is one trained on all available data and is then used to make predictions on new data. A problem with most final models is that they suffer variance in their predictions. This means that each time you fit a model, you get a slightly different set of parameters that in turn will make slightly different predictions. Sometimes more and sometimes less skillful than what you expected. This can be […]
Read more