Skeleton-of-Thought: Parallel decoding speeds up and improves LLM output
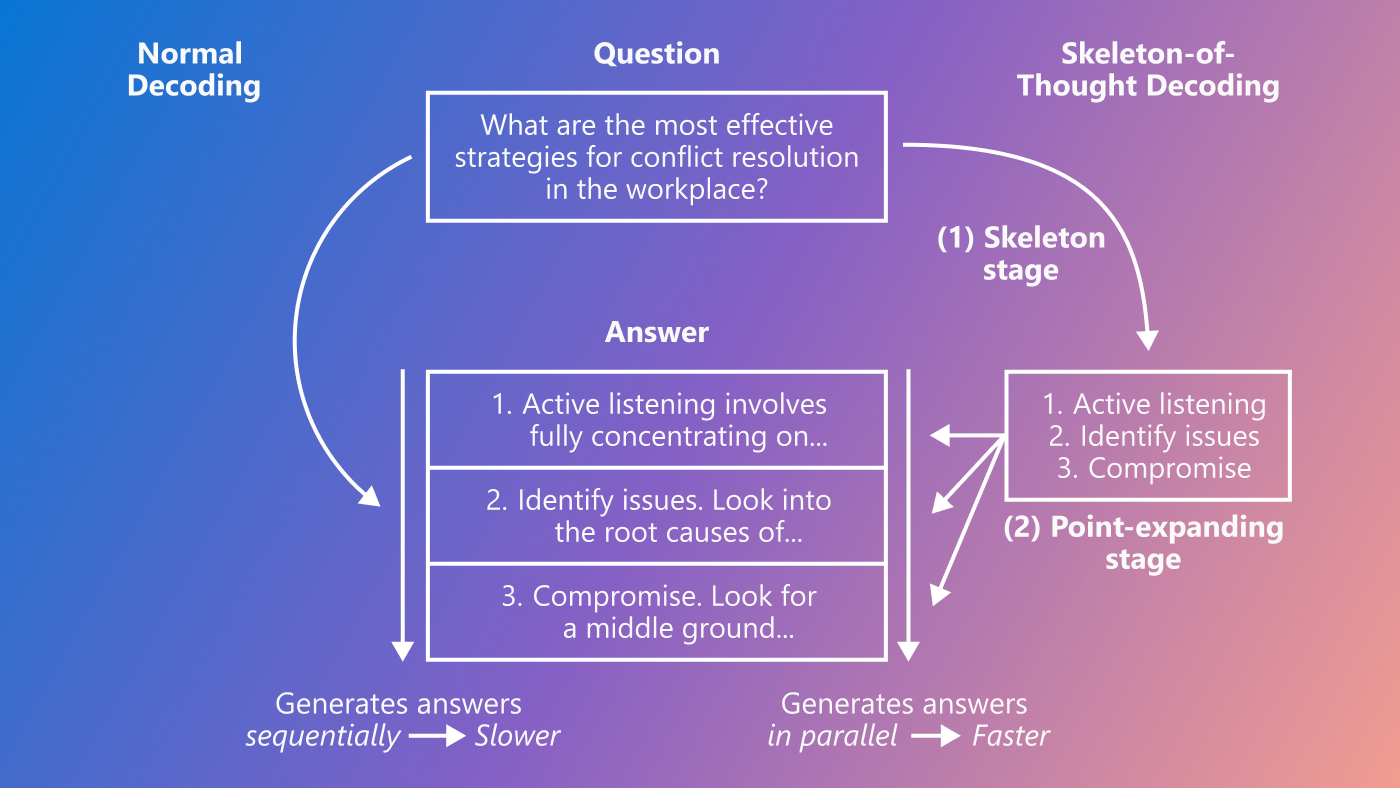
Large language models (LLMs) such as LLaMA and OpenAI’s GPT-4 are revolutionizing technology. However, one
Deep Learning, NLP, NMT, AI, ML
Large language models (LLMs) such as LLaMA and OpenAI’s GPT-4 are revolutionizing technology. However, one