Self-Supervised Learning for General-Purpose Audio Representation
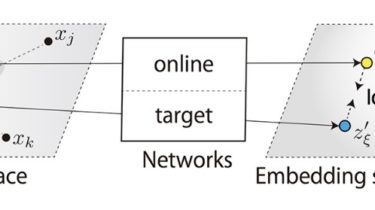
BYOL for Audio
This is a demo implementation of BYOL for Audio (BYOL-A), a self-supervised learning method for general-purpose audio representation, includes:
- Training code that can train models with arbitrary audio files.
- Evaluation code that can evaluate trained models with downstream tasks.
- Pretrained weights.
If you find BYOL-A useful in your research, please use the following BibTeX entry for citation.
@misc{niizumi2021byol-a,
title={BYOL for Audio: Self-Supervised Learning for General-Purpose Audio Representation},
author={Daisuke Niizumi and Daiki Takeuchi and Yasunori Ohishi and Noboru Harada and Kunio Kashino},
booktitle = {2021 International Joint Conference on Neural Networks, {IJCNN} 2021},
year={2021},
eprint={2103.06695},
archivePrefix={arXiv},
primaryClass={eess.AS}
}
Getting Started
-
Download external source files, and apply a patch. Our implementation uses the following.
curl -O https://raw.githubusercontent.com/lucidrains/byol-pytorch/2aa84ee18fafecaf35637da4657f92619e83876d/byol_pytorch/byol_pytorch.py
patch < byol_a/byol_pytorch.diff mv