Self-Damaging Contrastive Learning with python
SDCLR
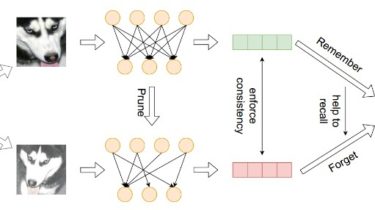
The recent breakthrough achieved by contrastive learning accelerates the pace for deploying unsupervised training on real-world data applications. However, unlabeled data in reality is commonly imbalanced and shows a long-tail distribution, and it is unclear how robustly the latest contrastive learning methods could perform in the practical scenario. This paper proposes to explicitly tackle this challenge, via a principled framework called Self-Damaging Contrastive Learning (SDCLR), to automatically balance the representation learning without knowing the classes. Our main inspiration is drawn from the recent finding that deep models have difficult-to-memorize samples, and those may be exposed through network pruning [1]. It is further natural to hypothesize that long-tail samples are also tougher for the model to learn well due to insufficient examples. Hence, the key innovation in SDCLR is