Recent Advances in Language Model Fine-tuning
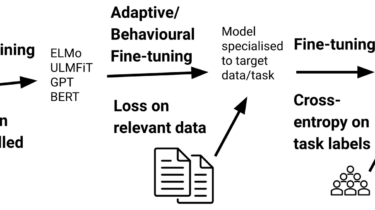
Fine-tuning a pre-trained language model (LM) has become the de facto standard for doing transfer learning in natural language processing. Over the last three years (Ruder, 2018), fine-tuning (Howard & Ruder, 2018) has superseded the use of feature extraction of pre-trained embeddings (Peters et al., 2018) while pre-trained language models are favoured over models trained on translation (McCann et al., 2018), natural language inference (Conneau et al., 2017), and other tasks due to their increased sample efficiency and performance (Zhang and Bowman, 2018). The empirical success of these methods has led to the development of ever larger models