Pytorch implementation of Tacotron
Tacotron-pytorch
A pytorch implementation of Tacotron: A Fully End-to-End Text-To-Speech Synthesis Model.
Data
I used LJSpeech dataset which consists of pairs of text script and wav files. The complete dataset (13,100 pairs) can be downloaded here. I referred https://github.com/keithito/tacotron for the preprocessing code.
File description
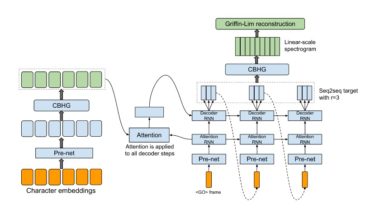
hyperparams.pyincludes all hyper parameters that are needed.data.pyloads training data and preprocess text to index and wav files to spectrogram. Preprocessing codes for text is in text/ directory.module.pycontains all methods, including CBHG, highway, prenet, and so on.network.pycontains networks including encoder, decoder and post-processing network.train.pyis for training.synthesis.pyis for generating TTS sample.
Training the network
- STEP 1. Download and extract LJSpeech data at any directory you want.
- STEP