Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation

Talking-Face_PC-AVS
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation (CVPR 2021)

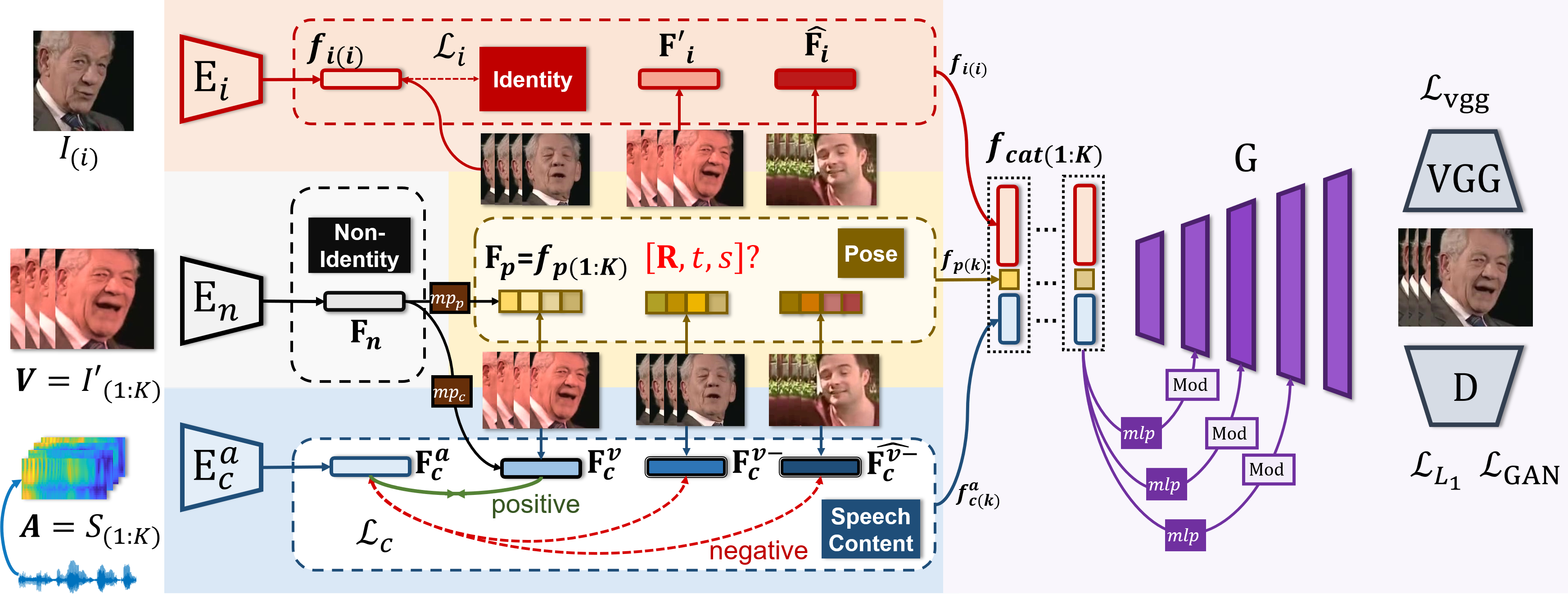
We propose Pose-Controllable Audio-Visual System (PC-AVS), which achieves free pose control when driving arbitrary talking faces with audios. Instead of learning pose motions from audios, we leverage another pose source video to compensate only for head motions. The key is to devise an implicit low-dimension pose code that is free of mouth shape or identity information. In this way, audio-visual representations are modularized into spaces of three key factors: speech content, head pose, and identity information.
Requirements
- Python 3.6 and Pytorch 1.3.0 are used. Basic requirements are listed in the ‘requirements.txt’.
pip install -r requirements.txt