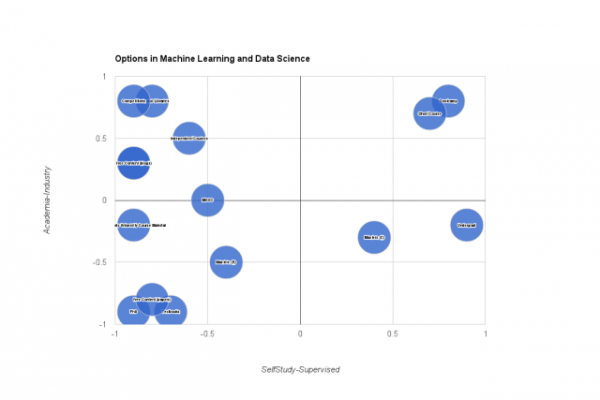
A Data-Driven Approach to Choosing Machine Learning Algorithms
Last Updated on April 4, 2018 If You Knew Which Algorithm or Algorithm Configuration To Use,You Would Not Need To Use Machine Learning There is no best machine learning algorithm or algorithm parameters. I want to cure you of this type of silver bullet mindset. I see these questions a lot, even daily: Which is the best machine learning algorithm? What is the mapping between machine learning algorithms and problems? What are the best parameters for a machine learning algorithm? There […]
Read more