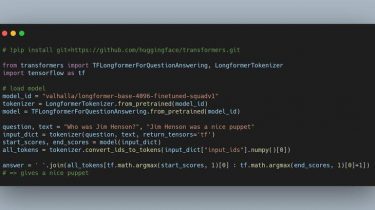
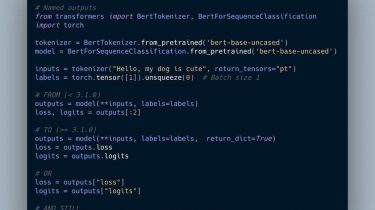
Hierarchical Prosody Modeling for Non-Autoregressive Speech Synthesis
Prosody modeling is an essential component in modern text-to-speech (TTS) frameworks. By explicitly providing prosody features to the TTS model, the style of synthesized utterances can thus be controlled… However, predicting natural and reasonable prosody at inference time is challenging. In this work, we analyzed the behavior of non-autoregressive TTS models under different prosody-modeling settings and proposed a hierarchical architecture, in which the prediction of phoneme-level prosody features are conditioned on the word-level prosody features. The proposed method outperforms other […]
Read more