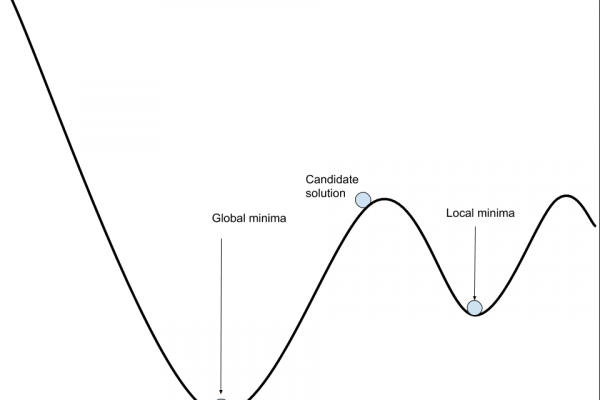
Why Training a Neural Network Is Hard
Last Updated on August 6, 2019 Or, Why Stochastic Gradient Descent Is Used to Train Neural Networks. Fitting a neural network involves using a training dataset to update the model weights to create a good mapping of inputs to outputs. This training process is solved using an optimization algorithm that searches through a space of possible values for the neural network model weights for a set of weights that results in good performance on the training dataset. In this post, […]
Read more







