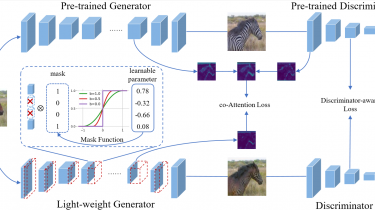
Close Category Generalization
Out-of-distribution generalization is a core challenge in machine learning. We introduce and propose a solution to a new type of out-of-distribution evaluation, which we call close category generalization… This task specifies how a classifier should extrapolate to unseen classes by considering a bi-criteria objective: (i) on in-distribution examples, output the correct label, and (ii) on out-of-distribution examples, output the label of the nearest neighbor in the training set. In addition to formalizing this problem, we present a new training algorithm […]
Read more