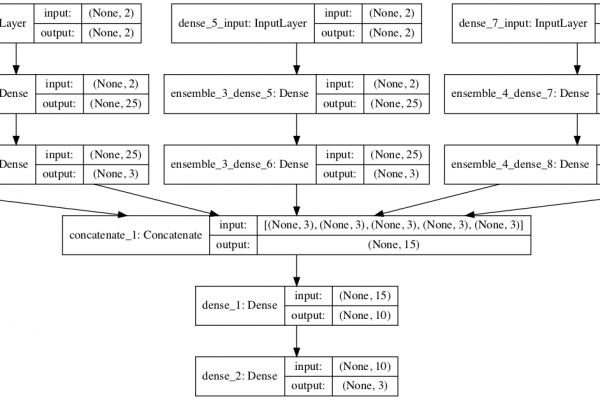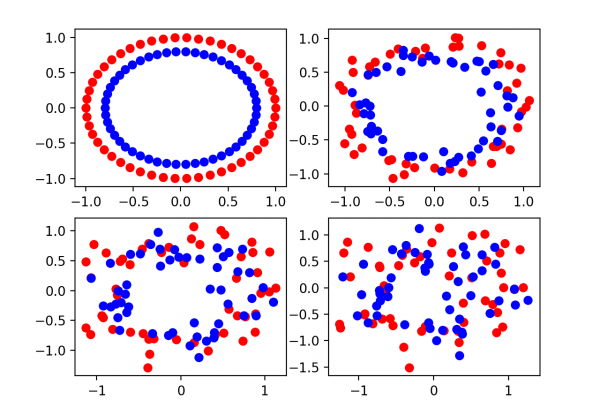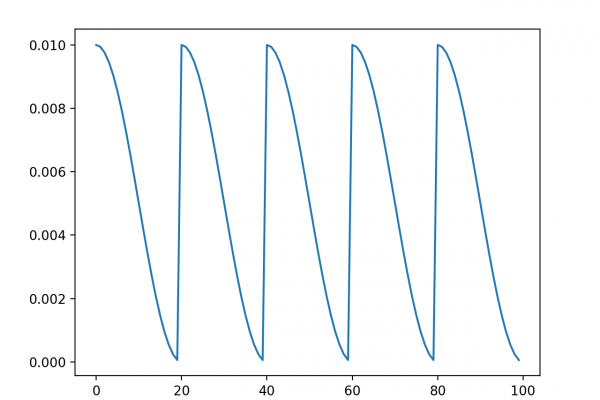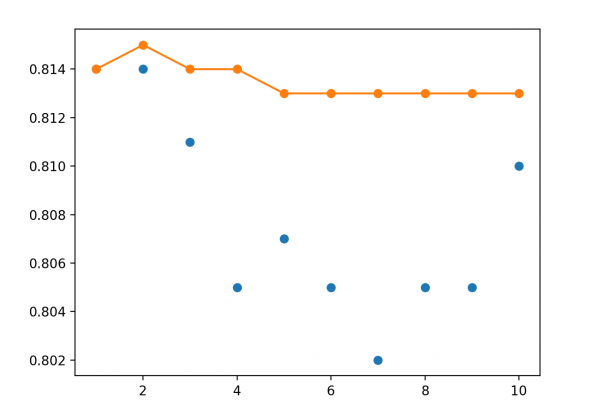
How to Develop a Weighted Average Ensemble for Deep Learning Neural Networks
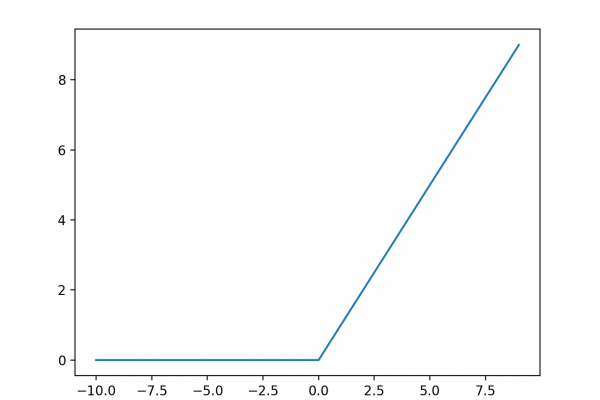
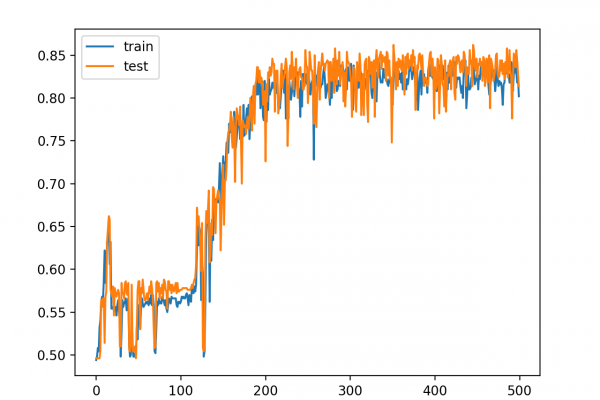
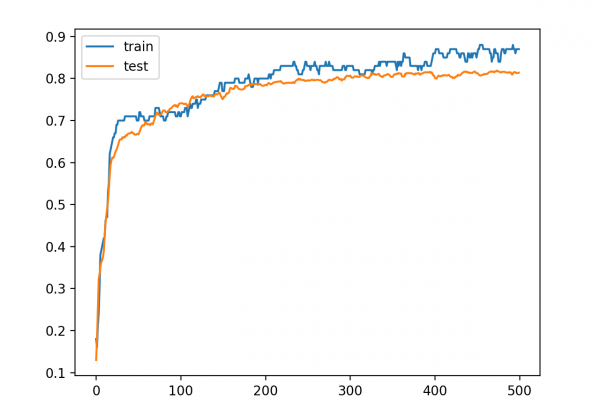
Last Updated on August 25, 2020 A modeling averaging ensemble combines the prediction from each model equally and often results in better performance on average than a given single model. Sometimes there are very good models that we wish to contribute more to an ensemble prediction, and perhaps less skillful models that may be useful but should contribute less to an ensemble prediction. A weighted average ensemble is an approach that allows multiple models to contribute to a prediction in […]
Read more