Node Similarity Preserving Graph Convolutional Networks
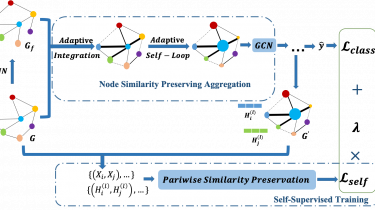
Graph Neural Networks (GNNs) have achieved tremendous success in various real-world applications due to their strong ability in graph representation learning. GNNs explore the graph structure and node features by aggregating and transforming information within node neighborhoods… However, through theoretical and empirical analysis, we reveal that the aggregation process of GNNs tends to destroy node similarity in the original feature space. There are many scenarios where node similarity plays a crucial role. Thus, it has motivated the proposed framework SimP-GCN […]
Read more







