How to Develop Multivariate Multi-Step Time Series Forecasting Models for Air Pollution
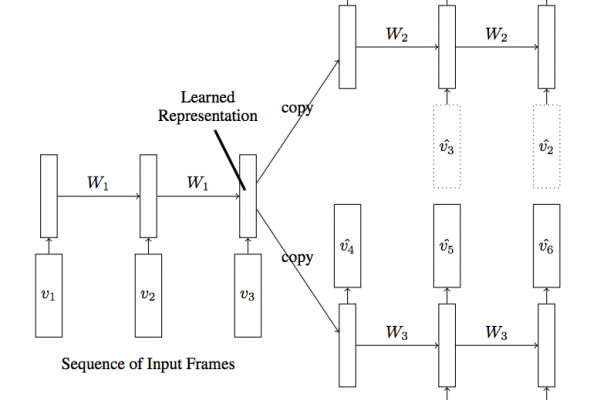
Last Updated on August 28, 2020 Real-world time series forecasting is challenging for a whole host of reasons not limited to problem features such as having multiple input variables, the requirement to predict multiple time steps, and the need to perform the same type of prediction for multiple physical sites. The EMC Data Science Global Hackathon dataset, or the ‘Air Quality Prediction’ dataset for short, describes weather conditions at multiple sites and requires a prediction of air quality measurements over […]
Read more