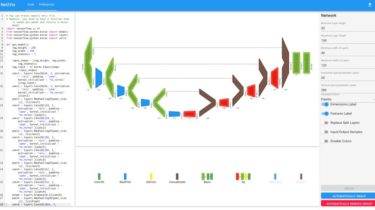
An Agnostic Object Detection Framework
cevision End-to-End Object Detection Framework – Pluggable to any Training Library: Fastai, Pytorch-Lightning with more to come. Installation pip install icevision[all] Important: We currently only support Linux/MacOS. Why IceVision? IceVision is an Object-Detection Framework that connects to different libraries/frameworks such as Fastai, Pytorch Lightning, and Pytorch with more to come. Features a Unified Data API with out-of-the-box support for common annotation formats (COCO, VOC, etc.) The IceData repo hosts community maintained parsers and custom datasets Provides flexible model implementations with […]
Read more