A Python library for electronic structure pre/post-processing
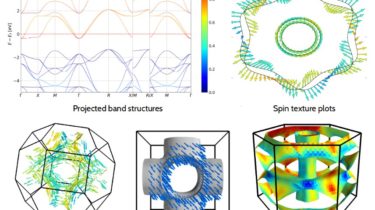
PyProcar PyProcar is a robust, open-source Python library used for pre- and post-processing of the electronic structure data coming from DFT calculations. PyProcar provides a set of functions that manage data obtained from the PROCAR format. Basically, the PROCAR format is a projection of the Kohn-Sham states over atomic orbitals. That projection is performed to every k-point in the considered mesh, every energy band and every atom. PyProcar is capable of performing a multitude of tasks including plotting plain and […]
Read more