HuggingFace, IISc partner to supercharge model building on India’s diverse languages
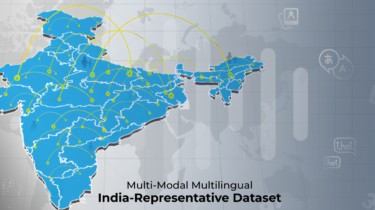
The Indian Institute of Science IISc and ARTPARK partner with Hugging Face to enable developers across the globe to access Vaani, India’s most diverse open-source, multi-modal, multi-lingual dataset. Both organisations share a commitment to building inclusive, accessible, and state-of-the-art AI technologies that honor linguistic and cultural diversity. Partnership The partnership between Hugging Face and IISc/ARTPARK aims to increase the accessibility and improve usability of the Vaani dataset, encouraging the development of AI
Read more