A python library that helps you read text from an unknown charset encoding
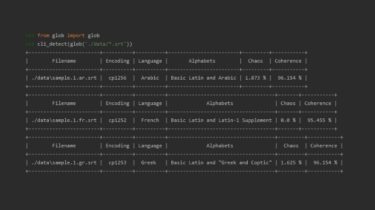
Charset Normalizer Library that help you read text from unknown charset encoding. Project motivated by chardet, I’m trying to resolve the issue by taking another approach. All IANA character set names for which the Python core library provides codecs are supported. Introduction This library aim to assist you in finding what encoding suit the best to content. It DOES NOT try to uncover the originating encoding, in fact this program does not care about it. By originating we means the […]
Read more