Self-Supervised Contrastive Learning of Music Spectrograms
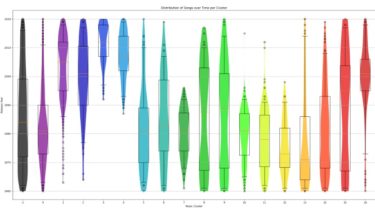
Self-Supervised Music Analysis Self-Supervised Contrastive Learning of Music Spectrograms. Dataset Songs on the Billboard Year End Hot 100 were collected from the years 1960-2020. This list tracks the top songs of the US market for a given calendar year based on aggregating metrics including streaming plays, physical and digital purchases, radio plays, etc. In total the dataset includes 5737 songs, excluding some songs which could not be found and some which are duplicates across multiple years. It’s worth noting that […]
Read more