A lightweight Python robot simulator for JupyterLab and Notebooks
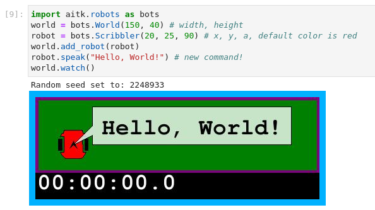
aitk.robots A lightweight Python robot simulator for JupyterLab, Notebooks, and other Python environments. Goals A lightweight mobile robotics simulator Usable in the classroom, research, or exploration Explore wheeled robots with range, cameras, smell, and light sensors Operate quickly without a huge amount of resources Create reproducible experiments Designed for exposition, experimentation, and analysis Sensors designed for somewhat realistic problems (such as image recognition) Especially designed to work easily with Machine Learning and Artificial Intelligence systems Installation For the core operations, […]
Read more