A script for Git-aware customization of the command prompt in Bash and zsh
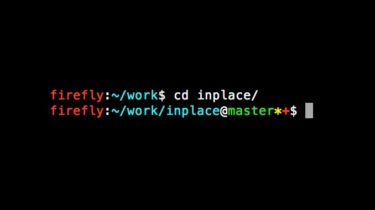
ps1.py Here we have yet another script for Git-aware customization of the command prompt in Bash and zsh. Unlike all the other scripts, I wrote this one, so it’s better. Features: lets you know if you have mail in $MAIL shows chroot and virtualenv prompt prefixes automatically truncates the current directory path if it gets too long shows the status of the current Git repository (see below) thoroughly documented and easily customizable supports both Bash and zsh can optionally output […]
Read more