Check and write all account info + Check nitro on account
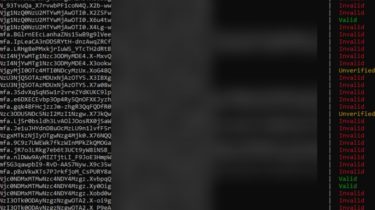
Check and write all account info + Check nitro on account Also check https://github.com/GuFFy12/Discord-Token-Parser (Parse discord tokens from any file, even if there is other shit in the file with them.) I have a great desire to remake this shit code, but I’m too lazy😔 JS EDITION: https://github.com/amfero/DiscordTokenChecker (I will contribute here (Py is 🤢)) TS EDITION: https://github.com/cattyngmd/DiscordTokenChecker-ts PY EDITION: https://github.com/GuFFy12/Discord-Token-Checker Output data: Token.rat Nitro: {Nitro or Classic or No} Billing: {Valid or Invalid or No} Username: lol#1337 Language: ru […]
Read more