Manage your exceptions in Python like a PRO
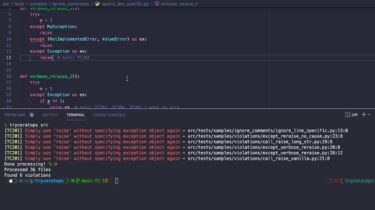
tryceratops Manage your exceptions in Python like a PRO. Installation and usage Installation pip install tryceratops Usage tryceratops [filename or dir…] You can enable experimental analyzers by running: tryceratops –experimental [filename or dir…] You can ignore specific violations by using: –ignore TCXXX repeatedly: tryceratops –ignore TC201 –ignore TC202 [filename or dir…] You can exclude dirs by using: –exclude dir/path repeatedly: tryceratops –exclude tests –exclude .venv [filename or dir…] Violations All violations and its descriptions can be found in docs. Ignoring […]
Read more