Discord.py Gaming Bot for fun & engaging discord minigames
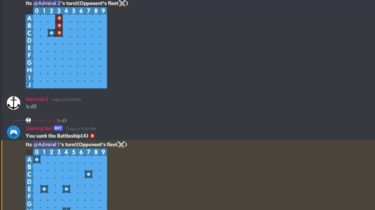
Discord.py-Gaming-Bot Discord.py Gaming Bot for fun & engaging discord minigames. Description 📝: An open source discord-py bot, made in python, which includes various minigames!🎮 (Scroll down for images!) Game List 📜: -Battleships(Completed) 🚢 -TicTacToe(WIP) ❌ -Uno(Planned) 🎴 -More ➕ Requirements🖥️: aiohttp==3.7.4.post0 async-timeout==3.0.1 attrs==21.2.0 chardet==4.0.0 discord==1.7.3 discord.py==1.7.3 idna==3.2 multidict==5.1.0 typing-extensions==3.10.0.0 yarl==1.6.3 Pip🐍: pip install discord Installation📥: git clone https://github.com/Wordsetter0/Discord.py-Gaming-Bot Usage⚙️: Type in your token in TOKEN.txt and you should be good to go Default bot image is provided in bot/boticon.png Images: […]
Read more