A Python-based application demonstrating various search algorithms
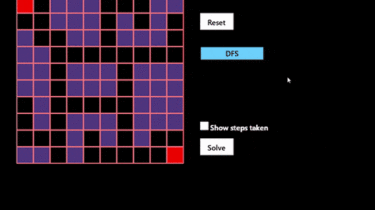
Algorithmic-Maze-Runner A Python-based application demonstrating various search algorithms, namely Depth-First Search (DFS), Breadth-First Search (BFS), and the A* Search (using the Manhattan Distance Heuristic) Running the .py File Clone the repository Install dependencies by entering pip install – r requirements.txt Run the .py file Files main.py: python file for application main.exe: executable version of main.py GitHub https://github.com/flintlok/Algorithmic-Maze-Runner
Read more