A tiny tool using script for schema to schedule one day
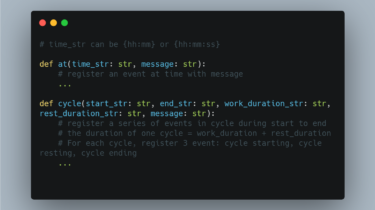
Schemdule Schemdule is a tiny tool using script for schema to schedule one day and remind you to do something during a day. Usage $ pip install schemdule Write a Schema It’s a pure python script, so you can use any python statement in it. Schemdule provide at and cycle functions for registering events. # time_str can be {hh:mm} or {hh:mm:ss} def at(time_str: str, message: str): # register an event at time with message … def cycle(start_str: str, end_str: str, […]
Read more