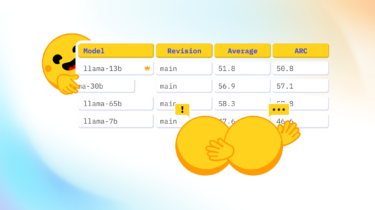
Visualize and understand GPU memory in PyTorch
You must be familiar with this message 🤬: RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 7.93 GiB total capacity; 6.00 GiB already allocated; 14.88 MiB free; 6.00 GiB reserved in total by PyTorch) While it’s easy to see that GPU memory is full, understanding why and how to fix it can be more challenging. In
Read more