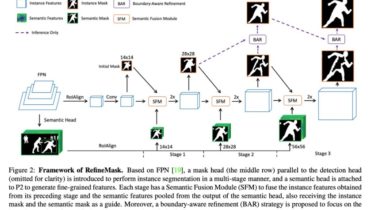
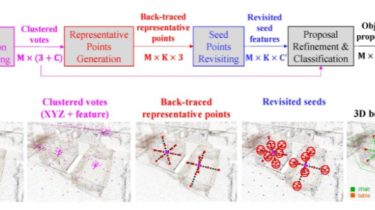
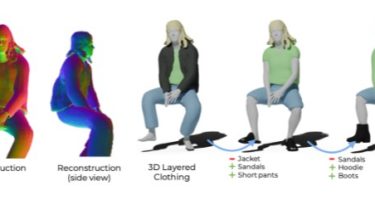
New Anaphora and Co-reference Resolution Technique for Biographies
This article was published as a part of the Data Science Blogathon Introduction Biographies of many famous personalities are very insightful and inspiring. Although, one may not want to read the whole document. In order to just get the important points from the biography, one can generate a summary of the biography. The summary is generated by giving weights to all the words. Sometimes, anaphoras can be predicted by the machine as a separate word which in return produces a less […]
Read more