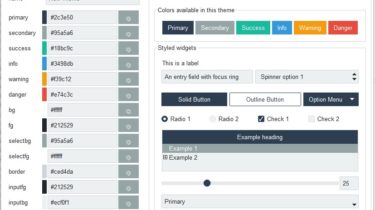
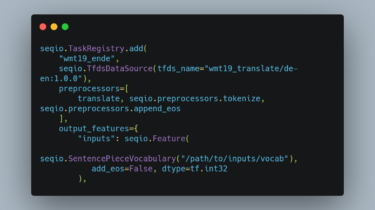
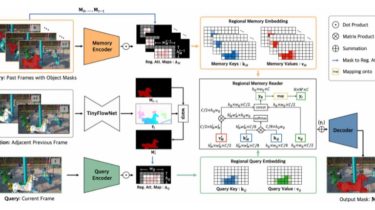
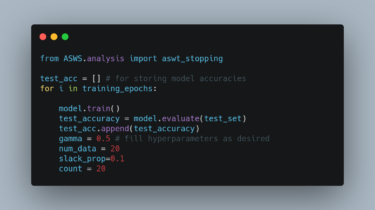
Invert and perturb GAN images for test-time ensembling
GAN Ensembling Ensembling with Deep Generative Views.Lucy Chai, Jun-Yan Zhu, Eli Shechtman, Phillip Isola, Richard ZhangCVPR 2021 Prerequisites Linux Python 3 NVIDIA GPU + CUDA CuDNN Table of Contents: Colab – run a limited demo version without local installation Setup – download required resources Quickstart – short demonstration code snippet Notebooks – jupyter notebooks for visualization Pipeline – details on full pipeline We project an input image into the latent space of a pre-trained GAN and perturb it slightly to […]
Read more