notebookJS: seamless JavaScript integration in Python Notebooks
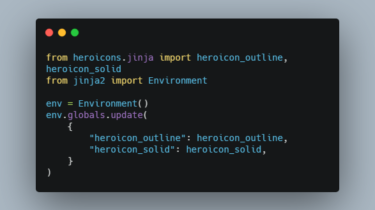
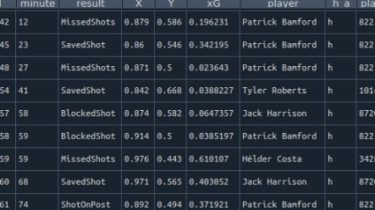
notebookJS notebookJS enables the execution of custom JavaScript code in Python Notebooks (Jupyter Notebook and Google Colab). This Python library can be useful for implementing and reusing interactive Data Visualizations in the Notebook environment. notebookJS takes care of downloading and handling Javascript libraries and CSS stylesheets from the web. Furthermore, it supports bidirectional communication between Python and JavaScript. User interactions in HTML/JavaScript can trigger Python callbacks that process data on demand and send the results back to the front-end code. […]
Read more