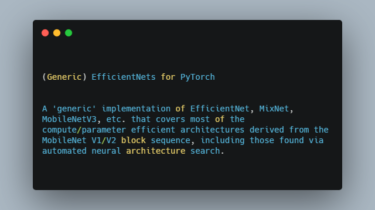
Generic EfficientNets for PyTorch
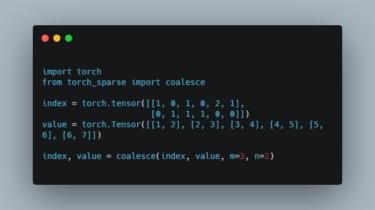
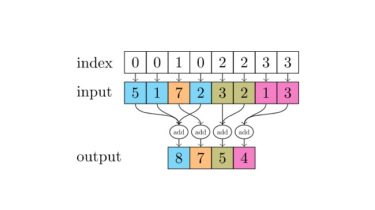
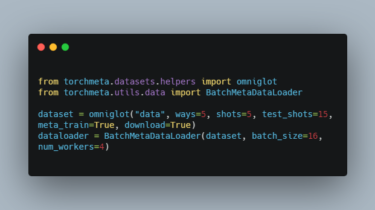
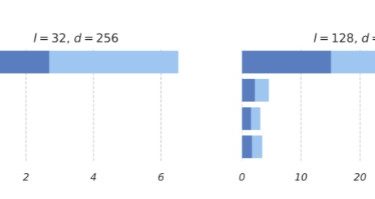
(Generic) EfficientNets for PyTorch A ‘generic’ implementation of EfficientNet, MixNet, MobileNetV3, etc. that covers most of the compute/parameter efficient architectures derived from the MobileNet V1/V2 block sequence, including those found via automated neural architecture search. All models are implemented by GenEfficientNet or MobileNetV3 classes, with string based architecture definitions to configure the block layouts (idea from here) Models Implemented models include: I originally implemented and trained some these models with code here, this repository contains just the GenEfficientNet models, validation, […]
Read more