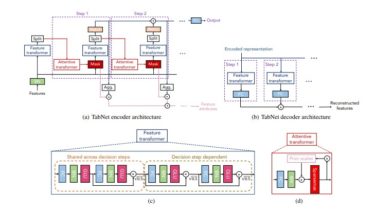
TabNet : Attentive Interpretable Tabular Learning
TabNet : Attentive Interpretable Tabular Learning This is a pyTorch implementation of Tabnet (Arik, S. O., & Pfister, T. (2019). TabNet: Attentive Interpretable Tabular Learning. arXiv preprint arXiv:1908.07442.) https://arxiv.org/pdf/1908.07442.pdf. Easy installation You can install using pip by running:pip install pytorch-tabnet Source code If you wan to use it locally within a docker container: git clone [email protected]:dreamquark-ai/tabnet.git cd tabnet to get inside the repository CPU only make start to build and get inside the container GPU make start-gpu to build and […]
Read more