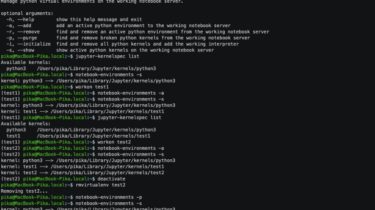
Manage python virtual environments on the working notebook server
notebook-environments Manage python virtual environments on the working notebook server. Installation It is recommended to use this package together with virtualenv and virtualenvwrapper to work with python virtual environments more suitable. Make sure the installed python interpreters work without errors on the current operating system. To install this package as a standalone application with the command-line interface you are to run the following command: sudo sh -c “$(curl https://raw.githubusercontent.com/vladpunko/notebook-environments/master/install.sh)” Use the package manager pip to install notebook-environments without the command-line […]
Read more