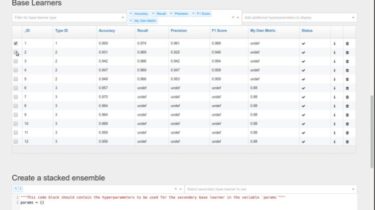
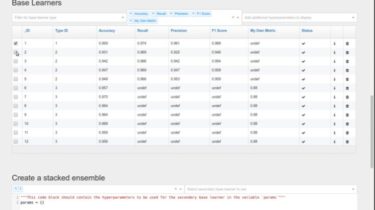
GitHub action for sspanel automatically checks in to get free traffic quota
GitHub – inokoe/SSPanel_Checkin: GitHub action for sspanel automatically checks in to get free traffic quota GitHub action for sspanel automatically checks in to get free traffic quota – GitHub – inokoe/SSPanel_Checkin: GitHub action for sspanel automatically checks in to get free traffic quota
Read more