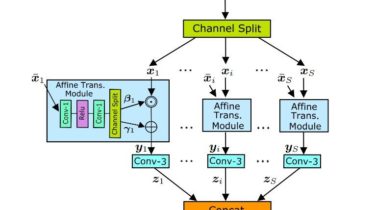
A Deep Learning based project for colorizing and restoring old images
Quick Start: The easiest way to colorize images using DeOldify (for free!) is here: DeOldify Image Colorization on DeepAI The most advanced version of DeOldify image colorization is available here, exclusively. Try a few images for free! MyHeritage In Color Image (artistic) |Video NEW Having trouble with the default image colorizer, aka “artistic”? Try the “stable” one below. It generally won’t produce colors that are as interesting as “artistic”, but the glitches are noticeably reduced. Image (stable) Instructions on how […]
Read more