Demonstration that AWS IAM policy evaluation docs are incorrect
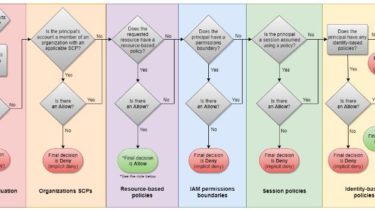
The flowchart from the AWS IAM policy evaluation documentation page, as of 2021-09-12, and dating back to at least 2018-12-27, is the following: The flowchart indicates that an Allow in a resource policy causes a final decision of Allow, before permissions boundaries have a chance to cause an implicit Deny. This would mean a resource policy could unilaterally grant access to a principal, circumventing its permissions boundary. However, this is only partially correct. Resource policies cannot unilaterally grant access to […]
Read more