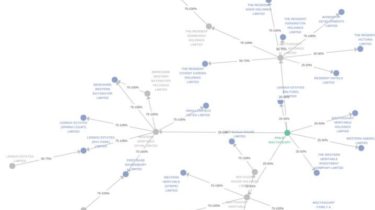
α-Indirect Control in Onion-like Networks
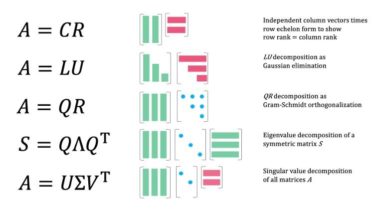
We propose a fast, accurate, and scalable algorithm to detect ultimate controlling entities in global corporate networks. α-ICON uses company-participant links to identify super-holders who exert control in networks with millions of nodes. By exploiting onion-like properties of such networks we iteratively peel off the hanging vertices until a dense core remains. This procedure allows for a dramatic speed-up, uncovers meaningful structures, and handles circular ownership by design. Read our paper with the applications. As a toy example, consider the […]
Read more