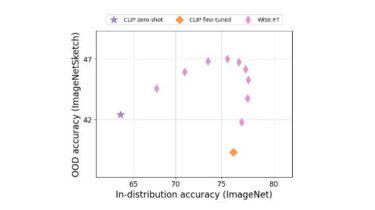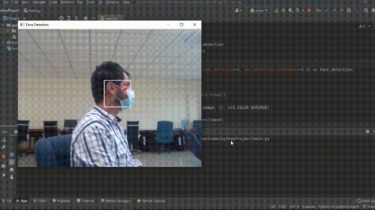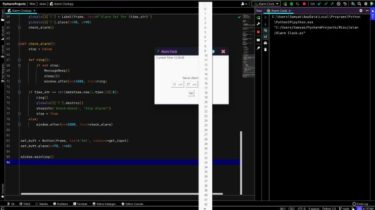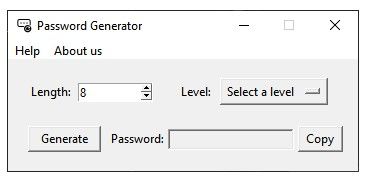
Different Shapes Made With PyQt5
Different Shapes Made With PyQt5 How to contribute? Your pull request must contain a file with the name of the shape’s. Moreover, your python file should be independent, meaning that it should have an instance of QApplication created GitHub https://github.com/Win-tharsh/PyQt6-Shapes
Read more