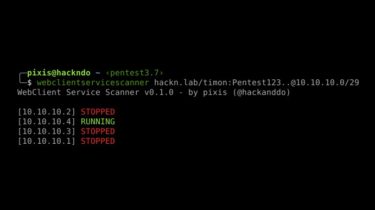
Rainbow: Combining Improvements in Deep Reinforcement Learning
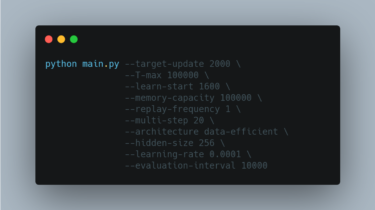
Rainbow Rainbow: Combining Improvements in Deep Reinforcement Learning [1]. Results and pretrained models can be found in the releases. [x] DQN [2] [x] Double DQN [3] [x] Prioritised Experience Replay [4] [x] Dueling Network Architecture [5] [x] Multi-step Returns [6] [x] Distributional RL [7] [x] Noisy Nets [8] Run the original Rainbow with the default arguments: python main.py Data-efficient Rainbow [9] can be run using the following options (note that the “unbounded” memory is implemented here in practice by manually […]
Read more