

A Telegram Userbot to play or streaming Audio and Video songs / files in Telegram Voice Chats
A Telegram Userbot to play or streaming Audio and Video songs / files in Telegram Voice Chats. 1) Installing NodeJS bash curl -fsSL https://deb.nodesource.com/setup_16.x | sudo -E bash – sudo apt-get install -y nodejs 2) Installing FFMPEG and Git bash sudo apt-get install git ffmpeg -y 3) Cloning the Repo bash git clone https://github.com/KennedyProject/Vcmusic-Userbot cd Vcmusic-Userbot 4) Rename `example.env` to `.env` and Fill
Read more
Google Developer Student Club I2IT/Clippin n grafting Backend
Presenting you, 🎉 Clippin’ n Grafting 🎉, your very own ecommerce website displaying all your artsy-craftsy stuff. Not only the exposure, but we aim to provide budding artists, budding entrepreneurs and just art enthusiasts a platform to sell, buy and just cruise through the amazing range of artistry that people desire to showcase! This repo focuses on the Django backend part of our Clippin’ n Grafting project Frontend – Backend –
Read more
Network automation Inventory manager
Welcome to Worktory’s documentation! Worktory is a python library created with the single purpose of simplifying the inventory management of network automation scripts. As the network automation ecosystem grows, several connection plugins and parsers are available, and several times choosing a library or a connection plugin restricts all the devices to the same connection method. Worktory tries to solve that problem giving the developer total flexibility for choosing the connector plugin and parsers for each device, at the same time […]
Read more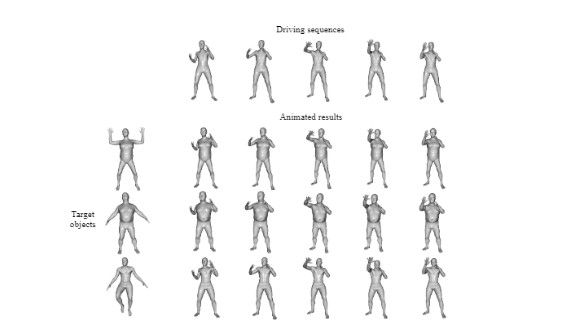
Convert lecture videos to slides in one line
About Convert lecture videos to slides in one line. Takes an input of a directory containing your lecture videos and outputs a directory containing .PDF files containing the slides of each lecture. (You can download the videos from Google Drive even if you only have View-Only permissions. Google it) The utility only captures slides when it detects that a slide has changed and does not capture every frame. Thus your pdf will be very close to the actual slides used. […]
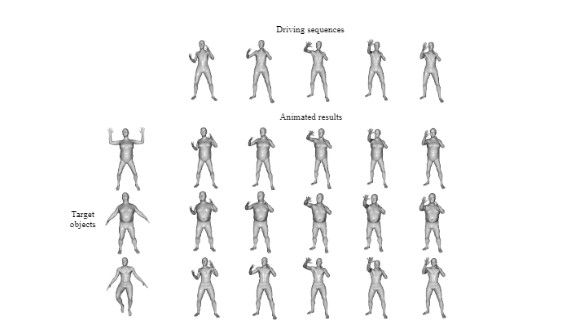
Read moreAniFormer: Data-driven 3D Animation with Transformer
This is the PyTorch implementation of our BMVC 2021 paper AniFormer: Data-driven 3D Animation with Transformer.Haoyu Chen, Hao Tang, Nicu Sebe, Guoying Zhao. Citation If you use our code or paper, please consider citing: @inproceedings{chen2021AniFormer, title={AniFormer: Data-driven 3D Animation withTransformer}, author={Chen, Haoyu and Tang, Hao and Sebe, Nicu and Zhao, Guoying}, booktitle={BMVC}, year={2021} } Dependencies Requirements: python3.6 numpy pytorch==1.1.0 and above trimesh Dataset preparation Please download DFAUST dataset
Read more
MEND: Fast Model Editing at Scale
Setup Environment This codebase uses Python 3.7.9. Other versions may work as well. Create a virtualenv (pyenv can help with this)and install the dependencies: $ python -m venv env $ source env/bin/activate (env) $ pip install -r requirements.txt Data You can download the data needed for this project fromthis Google Drive link.Unzip each sub-directory into mend/data and you should be good to go. Running the code Run MEND training/evaluation for distilGPT-2 on the wikitext editing problem with:
Read more
A python program will display all SSID usernames and SSID passwords you once connected to your laptop
Windows-Wifi-password-extractor This python program will display all SSID usernames and SSID passwords you once connected to your laptop How to run the program Run the following command python windows_wifi_passwd_extractor.py Requirements Python 3.X beautifultable should be installled on your system Note for the program to run successfully open the CMD/Terminal and type the following command pip install -r requirements.txt Build with Author License
Read more
Lighter and Faster YOLO is used to detect defect of X-ray weld image
This project is based on ultralytics/yolov3. LF-YOLO (Lighter and Faster YOLO) is used to detect defect of X-ray weld image. Download $ git clone https://github.com/lmomoy/LF-YOLO Train We provide multiple versions of LF-YOLO with different depths. $ python train.py –data coco.yaml –cfg LF-YOLO.yaml –weights ” –batch-size 1 LF-YOLO-1.25.yaml 1 LF-YOLO-0.75.yaml 1 LF-YOLO-0.5.yaml 1 Results We test our model on public dataset MS COCO, and it also achieves competitive results. Model size(pixels) mAPval0.5:0.95 mAPtest0.5:0.95
Read more