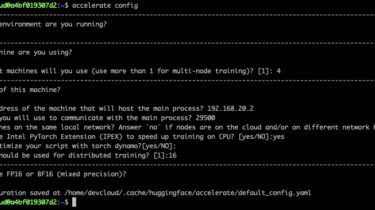
Deploy LLMs with Hugging Face Inference Endpoints
Open-source LLMs like Falcon, (Open-)LLaMA, X-Gen, StarCoder or RedPajama, have come a long way in recent months and can compete with closed-source models like ChatGPT or GPT4 for certain use cases. However, deploying these models in an efficient and optimized way still presents a challenge. In this blog post, we will show you how to deploy open-source
Read more