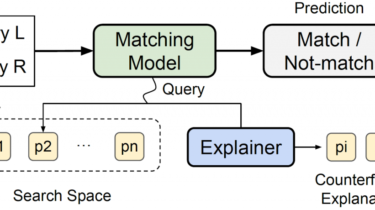
Minun and Explainable Entity Matching
Given two collections of entities, such as product listings, the entity matching (EM) problem aims to identify all pairs that refer to the same object in the real world, such as products, publications, businesses, etc. Recently, deep learning (DL) techniques have been widely applied to the EM problem and have achieved promising results. Unfortunately, the performance gain brought by DL techniques comes at the cost of reducing transparency and interpretability. The reason is that DL-based approaches are more like black-box […]
Read more





