NLP Unlocked: NER #005
NLP unleashed: unleashing the power of natural language processing.
Read moreDeep Learning, NLP, NMT, AI, ML
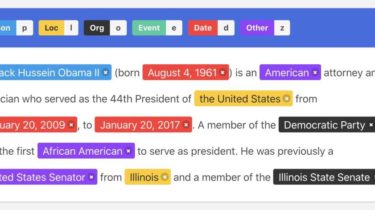
NLP unleashed: unleashing the power of natural language processing.
Read more
by Alper Özöner and Ali Utku Aydın This week, we have made some progress on the model selection as well as the representation of the eye tracking data we obtained from our EyeTribe eye tracker. First off, we have finally solved the problem of reading the raw data and its formatting. Amusingly, the formatting of
Read moreHave you struggled with file path handling in Python? With the pathlib module, the struggle is now over! You no longer need to scratch your head over code like this: >>> >>> path.rsplit(”, maxsplit=1)[0] And you don’t have to cringe at the verbosity of something like this: >>> >>> os.path.isfile(os.path.join(os.path.expanduser(‘~’), ‘realpython.txt’)) In this video course, you’ll learn how to: Work with file
Read more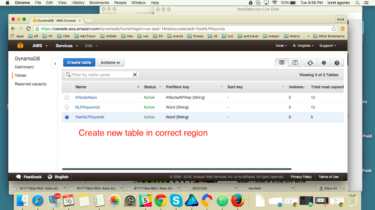
You might have noticed the dust on images in the icons and AWS UI. These are screenshot from 2016 (gulp), so reproducing these exact steps will be challenging to say the least. For example, at the time I felt generous enough to try Atom as my text editor — the redeeming value is that at least it was an Electron app. But S3 explorer? Fast forward five years, and, with some minor exceptions, it can still server as a valid […]
Read moreNLP unleashed: unleashing the power of natural language processing.
Read more
Amazon Sagemaker is a very popular service by AWS for building, training, and deploying machine learning (ML) models for any use case with fully managed infrastructure, tools, and workflows. In this post, I will use Amazon Sagemaker to build a binary text classification model using bert-base-uncasedmodel on
Read more
Photo by Nick
Read more
Getting a list of all the files and folders in a directory is a natural first step for many file-related operations in Python. When looking into it, though, you may be surprised to find various ways to go about it. When you’re faced with many ways of doing something, it can be a good indication that there’s no one-size-fits-all solution to your problems. Most likely, every solution will have its own advantages and trade-offs. This is the case when it […]
Read more
A case study on how we were able to scale an insurance aggregator framework up to 100 times.
Read more