
GloVe: Model Structure and Python Implementation
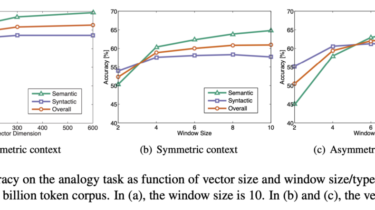
GloVe (Global Vectors) was proposed by Pennington, Socher, and Manning in 2014. It is a new global log-bilinear regression model that combines the advantages of the count-based and the prediction-based models. If you are new to word embedding models, feel free to check out my previous post on the
Read more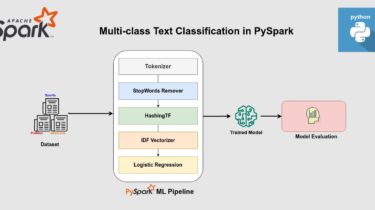
Multi-class Text Classification using Spark ML in Python
Build a News Article Classifier using the PySpark framework
Read more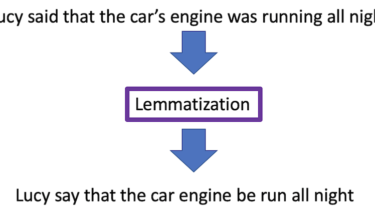
NLP Unlocked: Lemmatization #003
NLP unleashed: unleashing the power of natural language processing.
Read more

Easy implementation of K-Fold cross validation in python
Hi! Hope you’re in a good mood today. In this tutorial we are going to learn about K-fold cross validation and how to implement it in python, let’s begin with a brief introduction: Suppose you build a machine learning model to solve a problem, you split the dataset to train and test sets and then,
Read more
How not to pay Adobe and process multiple photos with Python (using the GPU no less!)
There is a very elegant technique to remove crowds from photos in which you just use a tripod and take multiple photos from the exact same spot. Every single picture might have tons of people, but every picture has people in different spots! So if you just average the pixels most of the crowd will just disappear. (Technically, the median works better, but I’m getting ahead of myself).
Read more
Insightful Data Science Web Applications with Streamlit
Insert a file uploader that accepts a single file at a time Streamlit is a free and open-source library that can be used with your favourite Python IDE to create web apps for data science and machine learning in a short time. You
Read more