
YAML: Python’s Missing Battery
Python is often marketed as a batteries-included language because it comes with almost everything you’d ever expect from a programming language. This statement is mostly true, as the standard library and the external modules cover a broad spectrum of programming needs. However, Python lacks built-in support for the YAML data format, commonly used for configuration and serialization. In this video course, you’ll learn how to work with YAML in Python using the available third-party libraries, with a focus on PyYAML. […]
Read more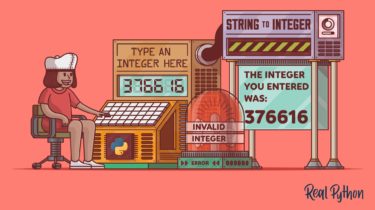
How to Read Python Input as Integers
If you’ve ever coded an interactive text-based application in Python, then you’ve probably found that you need a reliable way of asking the user for integers as input. It’s not enough simply to display a prompt and then gather keystrokes. You must check that the user’s input really represents an integer. If it doesn’t, then your code must react appropriately—typically by repeating the prompt. In this tutorial, you’ll learn how to create a reusable utility function that’ll guarantee valid integer […]
Read more
Speeding up text processing in Python (is hard)
If you’re doing text or string manipulation in Python, what do you do if your code is too slow? Assuming your algorithm is reasonably efficient, the next step is to try faster alternatives to Python: a compiled extension. Unfortunately, this is harder than it seems. Some options don’t offer an easy path to optimizations, others are actually slower. To see this limitation in action, we’ll consider some alternatives: Pure Python, with the default Python interpreter. Cython. mypyc. Rust. Pure Python, […]
Read more

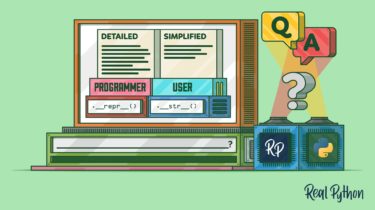
When Should You Use .__repr__() vs .__str__() in Python?
One of the most common tasks that a computer program performs is to display data. The program often displays this information to the program’s user. However, a program also needs to show information to the programmer developing and maintaining it. The information a programmer needs about an object differs from how the program should display the same object for the user, and that’s where .__repr__() vs .__str__() comes in. A Python object has several special methods that provide specific behavior. […]
Read moreSumming Values the Pythonic Way With sum()
Python’s built-in function sum() is an efficient and Pythonic way to sum a list of numeric values. Adding several numbers together is a common intermediate step in many computations, so sum() is a pretty handy tool for a Python programmer. As an additional and interesting use case, you can concatenate lists and tuples using sum(), which can be convenient when you need to flatten a list of lists. In this video course, you’ll learn how to: Sum numeric values by […]
Read more