Multi-Task Framework for Cross-Lingual Abstractive Summarization
MCLAS
Multi-Task Framework for Cross-Lingual Abstractive Summarization (MCLAS)
The code for ACL2021 paper Cross-Lingual Abstractive Summarization with Limited Parallel Resources (Paper).
Some codes are borrowed from PreSumm (https://github.com/nlpyang/PreSumm).
Environments
Python version: This code is in Python3.7
Package Requirements: torch==1.1.0, transformers, tensorboardX, multiprocess, pyrouge
Needs few changes to be compatible with torch 1.4.0~1.8.0, mainly tensor type (bool) bugs.
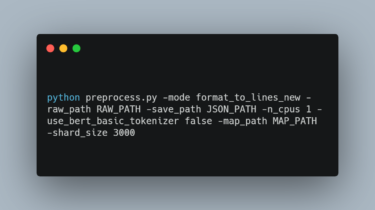
Data Preparation
To improve training efficiency, we preprocessed concatenated dataset (with target “monolingual summary + [LSEP] + cross-lingual summary”) and normal dataset (with target “cross-lingual summary”) in advance.
You can build your own dataset or download our preprocessed dataset.
Download Preprocessed dataset.
- En2De dataset: Google Drive Link.
- En2EnDe (concatenated) dataset: Google Drive Link.
- Zh2En dataset: Google Drive Link.
- Zh2ZhEn (concatenated) dataset: Google Drive Link.
- En2Zh