Multi-Speaker Adaptive Text-to-Speech Generation with python
StyleSpeech
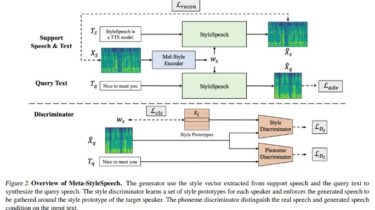
PyTorch Implementation of Meta-StyleSpeech : Multi-Speaker Adaptive Text-to-Speech Generation.

- [x] StyleSpeech (
naivebranch) - [x] Meta-StyleSpeech (
mainbranch)
Dependencies
You can install the Python dependencies with
pip3 install -r requirements.txt
Inference
You have to download pretrained models and put them in output/ckpt/LibriTTS/.
For English single-speaker TTS, run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --ref_audio path/to/reference_audio.wav --restore_step 200000 --mode single -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
The generated utterances will be put in output/result/. Your synthesized speech will have ref_audio‘s style.
Batch Inference
Batch inference is also supported, try
python3 synthesize.py --source preprocessed_data/LibriTTS/val.txt --restore_step 200000 --mode batch -p config/LibriTTS/preprocess.yaml -m config/LibriTTS/model.yaml -t config/LibriTTS/train.yaml
to synthesize all utterances in preprocessed_data/LibriTTS/val.txt. This can be viewed as a reconstruction of validation datasets referring to themselves